In this series of articles we create Apache Spark on Kubernetes deployment. Spark will be running in standalone cluster mode, not using Spark Kubernetes support as we do not want any Spark submit to spin-up new pods for us.
This is the Docker image for Spark Standalone cluster (Part 1), where we create a custom Docker image with our Spark distribution and scripts to start-up Spark master and Spark workers.
Complete guide comprises of 3 parts:
- Docker image for Spark Standalone cluster (Part 1)
- Submitting a job to Spark on Kubernetes (Part 2)
- Publishing Spark UIs on Kubernetes (Part 3)
Introduction
Although Apache Spark has support for running on Kubernetes, one may find himself neglecting this option for various reasons:
- Spark Submit creates pods by itself, which gives control of resources from hands of engineers to submitters
- Volumes, secrets and ony other details have to specified through spark submit, which is confusing for administrators, who are usually used to define whole deployment
- Distribution of JAR files is tedious, preparing a correct shaded packaging and/or prepending the classpath is a hell
On the other side, given the full control of what is included in a Docker image and Kubernetes manifest:
- we can avoid all of the JAR distribution between driver program and workers, everything will be hand picked in the image design (we can even avoid fat jar)
- we have full control of resources in deployment - how many workers/executors are deployed is controlled by deployment manifest
Architecture
We want to deploy Spark using Standalone cluster mode on a fixed defined Kubernetes deployment. We will design a single Docker image for this purpose, but we will start using different startup commands inside it, designed for: master, worker and driver program respectively. There will be a role of worker, master and driver programs running on Kubernetes as depicted on figure:

Deployment architecture
Docker image
We will use Docker multi stage build. In build stage we download the Spark binaries and then in final stage we cherry-pick only needed binaries to final image. We can also parametrize the build with args:
ARG SPARK_VERSION=3.0.1
ARG HADOOP_VERSION=2.7
ARG SCALA_VERSION=2.12
To download a Spark binary, we can re-use ready made curlimages/curl image as a build phase in Dockerfile:
FROM curlimages/curl as build
ARG SPARK_VERSION
ARG HADOOP_VERSION
ENV UPSTREAM_FILE_NAME="spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz"
ENV LOCAL_FILE_NAME="/tmp/${UPSTREAM_FILE_NAME}"
RUN curl -# "$(curl -s https://www.apache.org/dyn/closer.cgi\?preferred\=true)spark/spark-${SPARK_VERSION}/${UPSTREAM_FILE_NAME}" --output "${LOCAL_FILE_NAME}"
ENV SPARK_TMP="/tmp/spark"
RUN mkdir ${SPARK_TMP}
RUN tar -xvzf "${LOCAL_FILE_NAME}" --strip-components 1 -C "${SPARK_TMP}"
RUN echo "${UPSTREAM_FILE_NAME}" > "${SPARK_TMP}/.spark-version"
Notice how we maintain precise control of file names on our local filesystem by enforcing the output filename /opt/spark/spark-3.0.1-bin-hadoop2.7.tgz with --output argument to curl.
We unpack the tgz into directory /tmp/spark under which we create a without named version (that is --strip-components 1 argument to tar.
When we download the distribution tgz, we instruct curl with --output to force our filename /tmp/spark-3.0.1-bin-hadoop2.7.tgz on local disk.
Now we can build the image with the build phase:
docker build -t michalklempa/spark-build-phase --target build .
Lets inspect what is inside:
> docker run -it --rm --entrypoint sh michalklempa/spark-build-phase
> pwd
/
> cd /tmp/spark
/tmp/spark > ls -alh
total 160K
total 164K
drwxr-xr-x 1 curl_use curl_gro 4.0K Dec 28 19:10 .
drwxrwxrwt 1 root root 4.0K Dec 28 19:09 ..
-rw-r--r-- 1 curl_use curl_gro 30 Dec 28 19:10 .spark-version
-rw-r--r-- 1 curl_use curl_gro 22.8K Aug 28 08:10 LICENSE
-rw-r--r-- 1 curl_use curl_gro 56.3K Aug 28 08:10 NOTICE
drwxr-xr-x 3 curl_use curl_gro 4.0K Dec 28 19:09 R
-rw-r--r-- 1 curl_use curl_gro 4.4K Aug 28 08:10 README.md
-rw-r--r-- 1 curl_use curl_gro 183 Aug 28 08:10 RELEASE
drwxr-xr-x 2 curl_use curl_gro 4.0K Dec 28 19:09 bin
drwxr-xr-x 2 curl_use curl_gro 4.0K Dec 28 19:10 conf
drwxr-xr-x 5 curl_use curl_gro 4.0K Dec 28 19:09 data
drwxr-xr-x 4 curl_use curl_gro 4.0K Dec 28 19:09 examples
drwxr-xr-x 2 curl_use curl_gro 16.0K Dec 28 19:10 jars
drwxr-xr-x 4 curl_use curl_gro 4.0K Dec 28 19:09 kubernetes
drwxr-xr-x 2 curl_use curl_gro 4.0K Dec 28 19:09 licenses
drwxr-xr-x 9 curl_use curl_gro 4.0K Dec 28 19:10 python
drwxr-xr-x 2 curl_use curl_gro 4.0K Dec 28 19:09 sbin
drwxr-xr-x 2 curl_use curl_gro 4.0K Dec 28 19:09 yarn
Note the listing and move to designing the final image phase:
FROM azul/zulu-openjdk-debian:11 as final
ARG SCALA_VERSION
ARG SPARK_VERSION
ARG SPARK_TMP="/tmp/spark"
ENV SPARK_HOME="/opt/spark"
RUN mkdir ${SPARK_HOME}
Now we can cherry-pick only needed Spark binaries using COPY with --from:
COPY --from=build ${SPARK_TMP}/bin ${SPARK_HOME}/bin
COPY --from=build ${SPARK_TMP}/conf ${SPARK_HOME}/conf
COPY --from=build ${SPARK_TMP}/jars ${SPARK_HOME}/jars
COPY --from=build ${SPARK_TMP}/LICENSE ${SPARK_HOME}/LICENSE
COPY --from=build ${SPARK_TMP}/NOTICE ${SPARK_HOME}/NOTICE
COPY --from=build ${SPARK_TMP}/README.md ${SPARK_HOME}/README.md
COPY --from=build ${SPARK_TMP}/RELEASE ${SPARK_HOME}/RELEASE
COPY --from=build ${SPARK_TMP}/sbin ${SPARK_HOME}/sbin
COPY --from=build ${SPARK_TMP}/.spark-version ${SPARK_HOME}/.spark-version
The .spark-version file is there for a future maintainer who will look inside the image without prior knowledge.
Startup scripts
We design 3 scripts for running:
- Spark Master (
master.sh) - Spark Worker (
worker.sh) - Driver program (
submit.sh)
Spark Master is the easiest one:
#!/bin/bash
env
export SPARK_PUBLIC_DNS=$(hostname -i)
java ${JAVA_OPTS} \
-cp "${SPARK_HOME}/conf:${SPARK_HOME}/jars/*" \
org.apache.spark.deploy.master.Master \
--host ${SPARK_PUBLIC_DNS} --port 7077 --webui-port 8080
Notice the SPARK_PUBLIC_DNS variable. This is used by Spark internals to advertise other components the address on which the service is reachable.
Since we are in Kubernetes cluster environment, pod DNS is changing every time it is created.
We can use ClusterIP service to make the master reachable from workers, but if we would do the same with workers, each worker would need a separated service which is hard to maintain.
Instead of that, we will force Spark to use IP addresses as seen above.
Once the worker pod connects to Spark master using balanced ClusterIP service (with exactly one backing pod for master), the master responds with advertising its IP address for further communication.
Same will hold true for workers, executors and driver program.
Worker scripts are very similar:
#!/bin/bash
env
export SPARK_PUBLIC_DNS=$(hostname -i)
java ${JAVA_OPTS} \
-cp "${SPARK_HOME}/conf:${SPARK_HOME}/jars/*" \
org.apache.spark.deploy.worker.Worker \
--port 7078 --webui-port 8080 \
${SPARK_MASTER_HOST}:${SPARK_MASTER_PORT}
Driver script is a bit more interesting:
#!/bin/bash
env
export SPARK_PUBLIC_DNS=$(hostname -i)
java ${JAVA_OPTS} \
-cp "${JAR}:${SPARK_HOME}/conf:${SPARK_HOME}/jars/*" \
org.apache.spark.deploy.SparkSubmit \
--deploy-mode client \
--master spark://${SPARK_MASTER_HOST}:${SPARK_MASTER_PORT} \
--class ${MAIN_CLASS} \
${SUBMIT_OPTS} \
--conf 'spark.driver.host='$(hostname -i) \
local://${JAR}
Notice the variables SPARK_MASTER_HOST and SPARK_MASTER_PORT, those are to be set from outside (either in docker-compose.yml or Kubernetes manifest.yml).
There are handy placeholders for anyone willing to just drop some more options on command-line:
JAVA_OPTS, for example to specify customlog4j.propertiesfileSUBMIT_OPTS, if custom options to spark submit are to be presented (e.g.--executor-coresetc.)
Interesting is the JAR variable. This should hold the location of our job jar, which should be present in all docker images used (since there is a local:// scheme used).
This file can be supplied to the running image via Kubernetes volume or build into your custom image.
The latter option is what we describe in next article in the series.
Build the Docker image:
docker build -t michalklempa/spark:3.0.1-hadoop2.7 .
Running with docker-compose
For now, lets test, we can get the Spark Standalone cluster up and running.
You will need Docker and Docker Compose.
To do that, we may use docker-compose.yml.
> docker-compose up
spark-master_1 | /bin/bash: warning: setlocale: LC_ALL: cannot change locale (en_US.UTF-8)
spark-master_1 | HOSTNAME=15bdc9c80df8
spark-master_1 | LANGUAGE=en_US:en
spark-master_1 | JAVA_HOME=/usr/lib/jvm/zulu11-ca-amd64
spark-master_1 | SPARK_MASTER_HOST=spark-master
spark-master_1 | PWD=/opt/spark
spark-master_1 | HOME=/root
spark-master_1 | LANG=en_US.UTF-8
spark-master_1 | SPARK_MASTER_PORT=7077
spark-master_1 | SHLVL=1
spark-master_1 | SPARK_HOME=/opt/spark
spark-master_1 | LC_ALL=en_US.UTF-8
spark-master_1 | PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/spark/bin
spark-master_1 | SPARK_SCALA_VERSION=2.12
spark-master_1 | _=/usr/bin/env
spark-master_1 | Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
spark-master_1 | 20/12/29 19:54:41 INFO Master: Started daemon with process name: 9@15bdc9c80df8
...
Spark master should listen on localhost:8080 as seen on next screenshot.
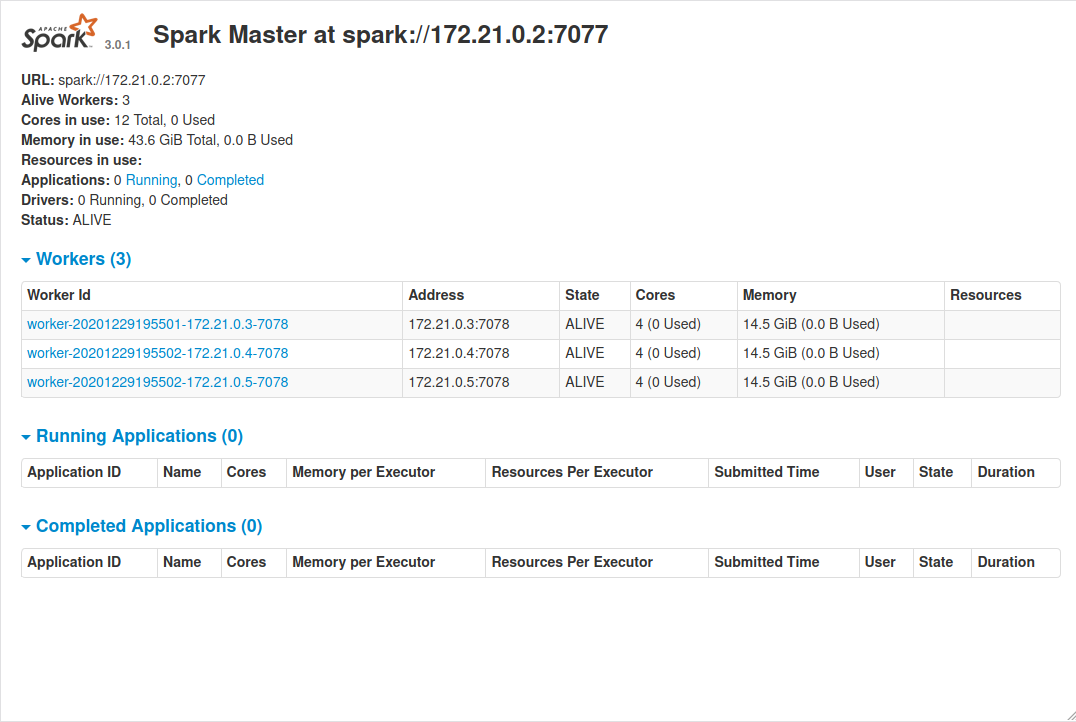
Spark master UI
Running with minikube
To test the setup on Kubernetes, install minikube.
There is a manifest.yml prepared to test the setup.
Just start your minikube cluster:
minikube start
The image pull policy is set to Never, so we should re-build the image in minikube environment:
eval $(minikube docker-env)
docker build -t michalklempa/spark:3.0.1-hadoop2.7 .
And apply the manifest:
kubectl apply -f manifest.yml
The pod list should look like:
> kubectl get pod
NAME READY STATUS RESTARTS AGE
spark-master-deployment-5694fcd6fb-nkqd9 1/1 Running 1 22h
spark-worker-deployment-57b94d48f-b9cm6 1/1 Running 1 22h
spark-worker-deployment-57b94d48f-xbhbf 1/1 Running 1 22h
The driver pod fails, since there is no Jar file present. We can test the setup by getting the published service URL from minikube:
> minikube service list
|-------------|---------------------|--------------|-------------------------|
| NAMESPACE | NAME | TARGET PORT | URL |
|-------------|---------------------|--------------|-------------------------|
| default | kubernetes | No node port |
| default | spark-master | No node port |
| default | spark-master-expose | http/8080 | http://172.17.0.2:32473 |
| kube-system | kube-dns | No node port |
|-------------|---------------------|--------------|-------------------------|
And pointing our browser to http://172.17.0.2:32473.
Conclusion
All the project files and roles are available in docker-spark github repository. Pre-built docker images available at hub.docker.com/r/michalklempa/spark.